728x90
📍목차
1. 손실함수란?
2. 손실함수의 종류
1. 손실함수 (Loss Function)란?
손실함수는 머신러닝/딥러닝 에서 모델이 예측한 값과 실제 정답의 차이를 나타내는 함수이다.
'학습 중에 알고리즘이 얼마나 잘못 예측하는지'를 확인하기 위한 함수로 최적화를 위해 오차를 최소화하는 것이 목적인 함수이다.
손실(loss)가 커질수록 학습이 잘 안되고 있음을 나타낸다.
모델을 학습하는 과정은 즉, 손실함수를 최소화 하는 가중치와 편향을 찾는 것이 목표이다.
손실함수를 목적함수, 비용함수 라고도 혼용해서 부르는데 정의는 완전히 다르다
손실함수 : 입력으로 받은 데이터를 하나씩 모두 오차를 계산하는 방식
비용함수 : 입력으로 들어온 데이터를 기반으로 모든 데이터의 비용을 계산하는 방식
목적함수 : 말그대로 어떠한 목적을 가지고 모델을 학습해 최적화하고자 하는 함수
따라서 크기로 따지면 목적함수 >= 비용함수 >= 손실함수 가 된다.
2. 손실함수의 종류
손실함수는 예측값에 따라 종류가 나눠진다
2.1 회귀모델
회귀는 연속적인 값을 예측하고자 하는 경우이다. 예를 들어 부동산 가격을 예측하는 것이다.
(1) MAE
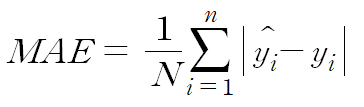
- 평균 절대 오차(Mean Absolute Error) 로 모든 절대 오차의 평균
- 절대값 때문에 어떤 식으로 오차가 발생했는지, 음수인지 양수인지 판단 불가능
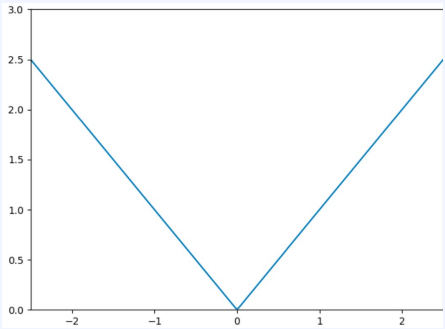
- MAE는 손실함수가 오차와 비례하여 일정하게 증가하는 특징
- 이상치에 덜 예민
(2) MSE

- 평균 제곱 오차(Mean Squared Error) 로 오차 제곱의 평균
- 제곱 연산으로 차이가 커질수록 값이 빠르게 증가하며 이상치에 예민

- MAE와 달리 최적 값에 가까워질 경우 굴곡형태이기 때문에 이동거리가 다르게 변화하여 최적 값에 수렴하기 용이하다
(3) RMSE

- MSE에 루트를 씌운 평균 제곱근 오차
- MSE에서 값을 제곱해서 생기는 왜곡이 줄어듬
2.2 분류모델
고양이인지 아닌지, 강아지 종류가 무엇인지 등 분류하고자 하는 경우
(1) Binary Cross-Entropy

- 이진 분류 문제에 사용한다
- 예를 들어 고양이인지 아닌지인 문제
- 예측값은 sigmoid함수를 거친 0~1 사이의 확률값이다
- 예측값이 1에 가까울수록 true일 확률이 크고, 0에 가까울수록 false일 확률이 크다

(2) Categorical Cross-Entropy

- 범주 교차 엔트로피로 분류해야 할 클래스가 3개 이상인 경우, 즉 멀티클래스 분류에 사용한다
- 예측값은 softmax 함수를 거친 0~1 사이의 확률 값을 갖는다
- 타겟 라벨은 원핫벡터로 구성되어 있고 예측값은 각 클래스에 속할 총합이 1인 확률 벡터로 나온다.
| 손실함수 | 용도 |
| 이진 크로스 엔트로피 | 이진 분류 |
| 범주형 크로스 엔트로피 | 다중 분류 |
| 평균 제곱 오차 | 회귀 문제 |
출처 및 참고
- https://velog.io/@gktnals108/%EC%86%90%EC%8B%A4-%ED%95%A8%EC%88%98Loss-Function
- https://velog.io/@kellypark1615/AIS7-%EC%86%90%EC%8B%A4%ED%95%A8%EC%88%98-Loss-Function%EC%9D%98-%EA%B0%9C%EB%85%90
'DL\ML > 기본개념' 카테고리의 다른 글
| [DL/기본개념] 옵티마이저(Optimizer) 종류 (0) | 2024.02.18 |
|---|---|
| [DL/기본개념] 역전파(Backpropagation) 알고리즘과 경사 하강법(Gradient descent) (2) | 2024.02.18 |
| [DL/기본개념] 활성화 함수(Activation Function) 개념 및 종류 (0) | 2024.02.05 |
| [DL/기본개념] 퍼셉트론(Perceptron) 개념 (0) | 2024.02.05 |



